
Better Defect Reduction: AI Applications in Your Quality Engineering Maturity Journey
The next time you sit down with your Chief Innovation Officer, bring up quality maturity as an agenda item. Artificial intelligence (AI) exists with …
READ MORE
In this article we are going to talk about one of our innovative new projects at Insighture, which uses Deep learning to bring down human intervention in intelligent web content scraping.
We, the Applied Research Team of Insighture, continuously focusing on solving real-world problems. We come up with novel hypotheses and validate them to make sure they reach production. This MVP is an outcome of one such effort.
Here our research project is using computer vision to annotate semantically incorrect web pages to relevant semantic HTML tags

Terabytes of content is created, rehashed and released to the internet continuously. There are many use cases requiring consumption of that content based on the industry or a specific scenarios. The structure of a web page content can easily be detected by reading the HTML semantics. However, the world isn’t a perfect place, and therefore we find many content websites have different semantics though they look more similar on the surface to the human eye. This only becomes a problem when a machine tries to understand them because of their diverse nature of underlying semantics.
As said, not all sites follow the correct HTML semantics when maintaining their websites—underlying HTML tags can be all over the place. For example, when we check a website from our naked eye, we can see a title and a paragraph. However, the actual code behind the scene may be using a standard <p> tag with a higher font weight and font size for a title instead of a <h1> tag. To determine the structure, the algorithm needs to be aware that the title is a title and the paragraph is a paragraph, which is impossible with the wrong HTML usage.
Typically converting unstructured content to structured content requires huge manpower and can be a monotonous lengthy process.
The Applied Research team at Insighture was presented with the task of looking into novel, efficient ways to solve the scalability problem described above.
We can look into this matter in two aspects of Deep learning. NLP vs Vision.
When we were thinking about the NLP approach, the one concept that came into everyone mind was topic modelling. In topic modelling, what happens is the computer looks at the content and comes up with some sort of a topic. These can be either predefined topics or else a topic that computers self learns depending on the frequencies of words. Challenge here is, most of the time names of those section/subsections are not always appearing in the content frequently. On the other hand, we can’t really limit ourselves to a set of predefined topics too. Another issue in this path is we can not limit ourselves to a single language as we deal with data from all around the world.
So the next thing we thought of is, can we use computer vision to detect differently? We decided to turn to computer vision. The logic behind this is the company’s current approach. As the first step, we are trying to mimic the current procedure but in an automated manner without involving humans.
We started the project with limited scope to annotate only heading tags (H1,..) and paragraph tags. Our evaluation criteria are the same as in object detection. We require our model to give named coordinates for an object (heading, subheading, paragraph, etc) detected on the web page. As resources, we had a subject matter expert on the web pages we are going to deal with, ML Engineers, Software Engineers, and DevOps Engineers.
We made sure the data is large and diverse enough to make our Minimum Lovable Product Minimum Lovable Product. All the datasets we made during the process were versioned with DVC, an open-source data and model versioning tool.
Applications of Computer Vision in the real world, ranging from medical diagnosis to self-driving cars. It spans across subject areas like image classification, object detection, image segmentation, landmark detection, etc.
So we thought to harness the power of computer vision in our scenario to identify and annotate the structure of the web contents which tags are not semantically correct. We needed our model to understand the look of the website and to annotate the sections for us.
With the Evolution of Deep Learning, We saw many different Neural networks, particularly Convolutional Neural networks, perform better for computer vision tasks.
We thought of approaching this as a Detection problem with the help of transfer learning. Transfer Learning is a concept in the Machine Learning and Deep Learning domain where it looks at the possibility of using stored knowledge of solving one problem in solving another different, yet related problem. For example, if a model is trained to identify cats correctly, the knowledge that the model gained regarding this classification task, can be used to identify cars correctly, after a small number of iterations on fine-tuning (gradient updates). The motivation behind this approach is driven by the practical difficulties in data gathering related to each domain and hardware or infrastructure limitations faced by researchers.
Learn more on transfer learning
For an Object Detection task, we use bounding boxes to describe the spatial location of an object. Here Let’s assume our object classes are heading and paragraphs. We then need to create our own dataset by drawing labelled bounding boxes around those in a webpage. Such Data annotations can be facilitated with platforms like
To determine our model’s performance, We need to split our dataset into training, validation, and testing data splits.

Then we split our data as train, validation and test set. This ensures there are no data leakages affecting our final evaluation of the model. The percentage of split taken into each set depends on how large our dataset is.
Since we decided upon turning to Computer Vision to tackle our problem, it is important to understand what we can do with image data. According to the literature, there are few different areas in computer vision.
Image classification: Given an image, identify which class it belongs to. This is done for single object images.
Object localization: This helps us to identify exactly where the object is present in the image given to it, by drawing a bounding box around the object.
Object detection: When multiple objects are present in a single picture, belonging to a single class or multiple classes, object detection tries to identify all of them and their respective classes. In most cases, localization is also used alongside this.
Instance segmentation: This can happen either when a single object is present or when multiple objects are present. What it does is identifies which pixels actually belong to that identified object. This means this can draw an outline around the identified object. Segmentation is highly used in medical image processing.
Landmark detection
Landmarks are the point of interest in an image. For example, if the image contains a face, landmarks will be around eyes, nose, mouth, eyebrows, jawlines, etc. This section of image processing looks at the detection of such landmarks. This is heavily used in emotion and gesture recognition.
For our use case, it is clear that what we need is object detection. Object detection has recorded tremendous growth in the recent past, helping out many industries. Its usage alongside object localization and classification had resulted in one of the most challenging topics in computer vision, empowering concepts like self-driving cars.
Object detection is a combination of a classifier and regressor, to classify which class the detected object belongs to and to localize the object detected, respectively.
In object detection we simply answer two questions
We used Faster RCNN, an improved version of the algorithm from the RCNN family which was developed by Ross Girshick et al in 2014.
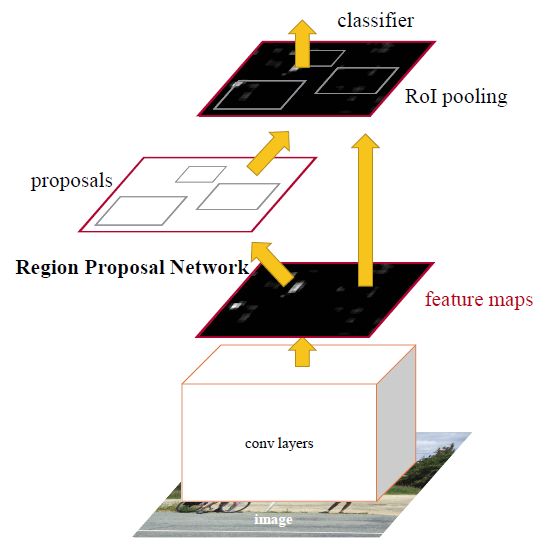
As you see above a Faster R-CNN object detection architecture is has a feature extraction layer,
If you like to know more about feature maps check this
which is a pre-trained CNN and followed by an Region Proposal Network (RPN) which is used to generate objects proposals and a classifier.
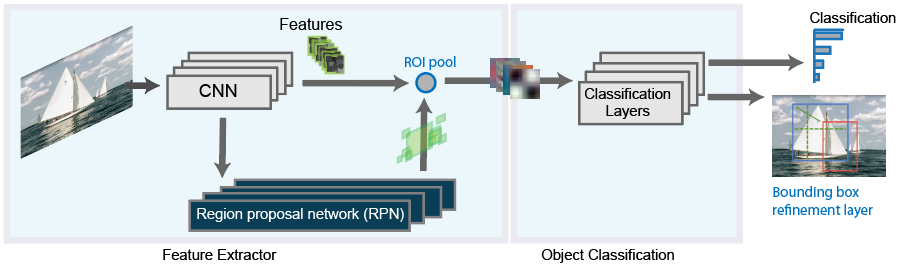
So the Faster RCNN ’s RPN is the main difference from its predecessor which trained to produce Region proposals directly without the need for any external mechanism like Selective Search. After this, we use ROI pooling and an upstream classifier and bounding box regressor similar to Fast R-CNN.
To put it in simpler terms, we can say that our model uses a pre-trained Faster RCNN model which was later fine-tuned on our own pre-processed data, which contains two object classes; paragraphs and headings. The model was evaluated on mAP and model checkpoints versioned with the same versioning tool we used for data versioning, i.e. DVC.
Know more about dvc here
As I mentioned earlier first step starts with a pre-trained CNN for this task we are using ResNet101pre trained on ImageNet classification
The Evaluation for these tasks done through mAP aka Mean Average Precision at some specific Intersection over Union aka IoU threshold (mAP@0.75) mAP penalizes when we miss a box that should be detected as well as another way when we detect something not relevant or duplicated.
Our results with a simple toy dataset and few epochs of training
| map | map@50 | map@75 |
|---|---|---|
| 52.608 | 83.399 | 54.087 |
With this blog post, we looked at how the Applied Research team at Insighture handled a certain Deep learning and Research related user story end to end
Note we are in the process to try out Transformers Network for these detections tasks by starting from facebook’s DEtection TRansformer (DETR) model by Carion et al. A encoder-decoder transformer with a convolutional backbone. Two heads are added on top of the decoder outputs in order to perform object detection: a linear layer for the class labels and an MLP (multi-layer perceptron) for the bounding boxes
The next time you sit down with your Chief Innovation Officer, bring up quality maturity as an agenda item. Artificial intelligence (AI) exists with …
READ MORE
AI has been an anticipated technological breakthrough, taking over most manual white-collar jobs today. PwC’s Global AI Study reveals that AI will …
READ MORE