
Better Defect Reduction: AI Applications in Your Quality Engineering Maturity Journey
The next time you sit down with your Chief Innovation Officer, bring up quality maturity as an agenda item. Artificial intelligence (AI) exists with …
READ MORE
Intoday’s digital landscape, where data is more valuable than ever, understanding the tools and technologies that enable efficient data management and analysis is crucial. One such technology, which has become a cornerstone for big data analytics, is the data lake.
Simply put, a data lake is a centralized repository designed to store, process, and secure large volumes of data in various formats — structured, semi-structured, and unstructured. Unlike traditional data storage systems, data lakes allow for the storage of raw data, keeping it in its native format until it is needed. This approach provides unparalleled flexibility and scalability, making data lakes an essential component of modern data architectures.
Data lakes are known for their:
While both data lakes and data warehouses are used for storing big data, they serve different purposes and are designed for different types of data analysis.
Data Warehouses: These are databases optimized for analyzing relational data from transactional systems and line-of-business applications. Data warehouses require data to be cleaned and structured in a specific schema before it can be used, making them ideal for operational reporting and structured data analysis.
Data Lakes: In contrast, data lakes are designed to store raw data — structured, semi-structured, and unstructured. This makes data lakes more flexible and better suited for exploratory data analysis, data discovery, and machine learning, where the structure of the data is not a limitation but an asset.
Understanding the distinction between data lakes and data warehouses is key to implementing an effective data management strategy that aligns with your organization’s analytics needs and capabilities.
Delving deeper into the architecture of data lakes reveals why they are such a powerful tool for handling big data. A data lake’s architecture is designed to store vast amounts of data while supporting complex processing and analytics. Let’s explore the core components that make up a data lake, focusing on storage, processing, management, and other critical aspects like data ingestion and metadata management.
A data lake comprises several key components, each playing a vital role in its functionality:
Storage: At its core, a data lake uses scalable storage solutions to accommodate the exponential growth of data. This storage is not just capacious but also flexible, allowing for the storage of data in various formats.
Processing: Data lakes employ powerful processing engines to run complex analytics and machine learning algorithms on large datasets. These engines can handle batch and real-time processing, offering insights into both historical and real-time data.
Management: Effective management tools are crucial for organizing data within the lake. These tools handle tasks such as data cataloging, security, and access control, ensuring that the data lake remains both accessible and secure.
A depiction of a data lake’s architecture.
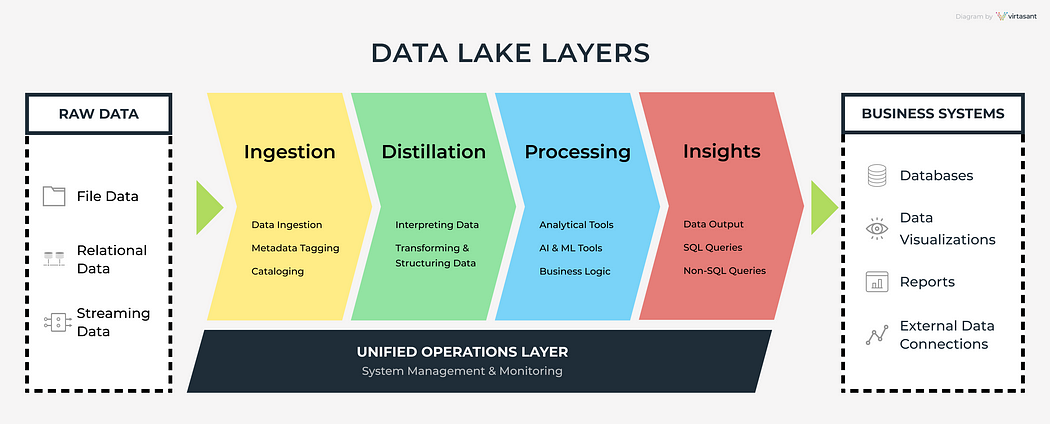
Data ingestion into a data lake can be performed in two primary ways:
Choosing between batch and real-time processing depends on the specific needs of the organization and the nature of the data being analyzed.
Using these formats can significantly reduce storage costs and improve query performance, making them an essential consideration in data lake architecture.
Metadata management and data cataloging are foundational to the usability and governance of a data lake. Metadata includes information about the data’s source, format, and lineage, which helps in understanding and managing the data effectively.
Efficient metadata management and data cataloging are critical for maintaining a well-organized, accessible, and secure data lake.
Data lakes have become a cornerstone for businesses aiming to enhance their analytical capabilities and derive actionable insights from their vast data reserves. By consolidating data in a single repository, companies can perform advanced analytics and machine learning, leading to informed decision-making and strategic advancements. This section explores how data lakes support business intelligence and analytics, underscored by case studies from Siemens and Grammarly, and discusses their integration with analytics tools and the role of machine learning.
Data lakes integrate effortlessly with a broad spectrum of analytical tools, unlocking extensive data’s potential. This compatibility enables real-time analytics and in-depth data exploration, leading to the development of predictive models. Platforms like Databricks SQL, and AWS analytics services allow direct data querying, making insights accessible for strategic decision-making.
The Medallion Architecture in Databricks
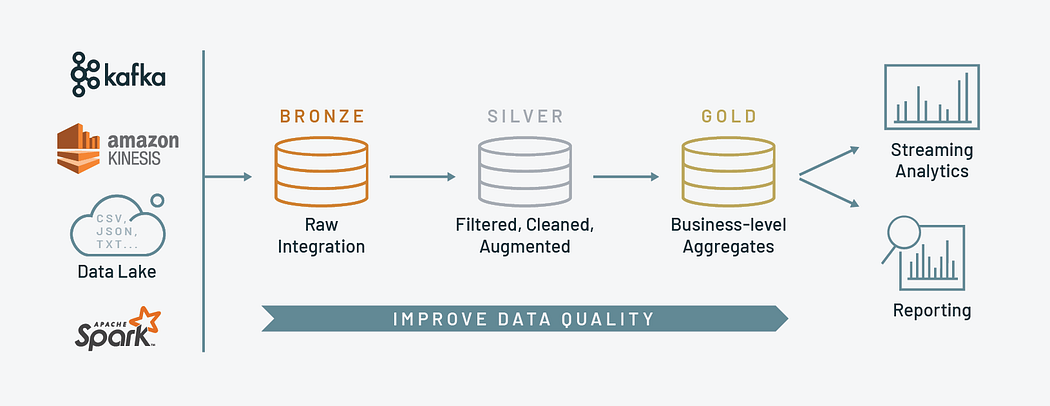
Data lakes are essential for CTOs, CIOs, and business leaders, acting as the foundation of data-driven initiatives. By consolidating varied data sources into one unified platform, data lakes facilitate advanced analytics, machine learning, and AI-driven applications. This consolidation is crucial for driving innovation and securing a competitive advantage, while also ensuring strategic alignment with business objectives to enhance organizational agility and market responsiveness.
The challenge for executives lies in marrying the technical complexities of data lake architecture with business needs. The focus is on crafting data lakes that are not just technologically advanced but are also strategic business assets, ensuring they enhance operational efficiency and decision-making. This involves a meticulous balance of security, governance, and compliance to secure sensitive data and meet regulatory standards, transforming data lakes into secure resources.
Aligning data lakes with business goals is crucial. Executives and strategists must map out how data lakes can amplify business priorities through better data accessibility and analytics, driving insightful decision-making. The adoption of data lakes significantly boosts operational efficiency by offering an integrated, real-time data view, facilitating a more dynamic and adaptable operational framework.
Moreover, the cultural shift towards a data-driven ethos is a key transformation. By democratizing data access and promoting data literacy across all levels, organizations nurture a culture where data underpins decision-making. This not only elevates productivity but also synergizes with strategic goals to spur ongoing innovation and growth.
Implementing and managing a data lake requires a comprehensive approach that involves collaboration among cross-functional teams, adherence to best practices, and the strategic use of advanced tools and technologies. This section delves into the collaborative frameworks and technical strategies that are fundamental for the effective deployment and scaling of data lakes, especially in environments that demand a high degree of technical proficiency.
Unlike the traditional ETL process, ELT is particularly suited for data lakes due to its efficiency in handling vast volumes of data.
Image depicting the basic difference between ETL and ELT
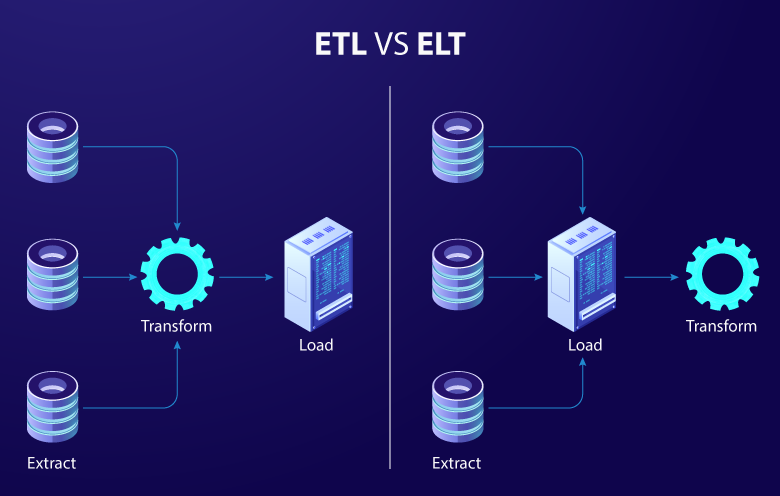
In ELT, data is extracted from the source systems, loaded into the data lake in its raw form, and then transformed as needed for specific analytics tasks. This approach leverages the processing power of modern data lake technologies to perform transformations, offering greater flexibility and speed.
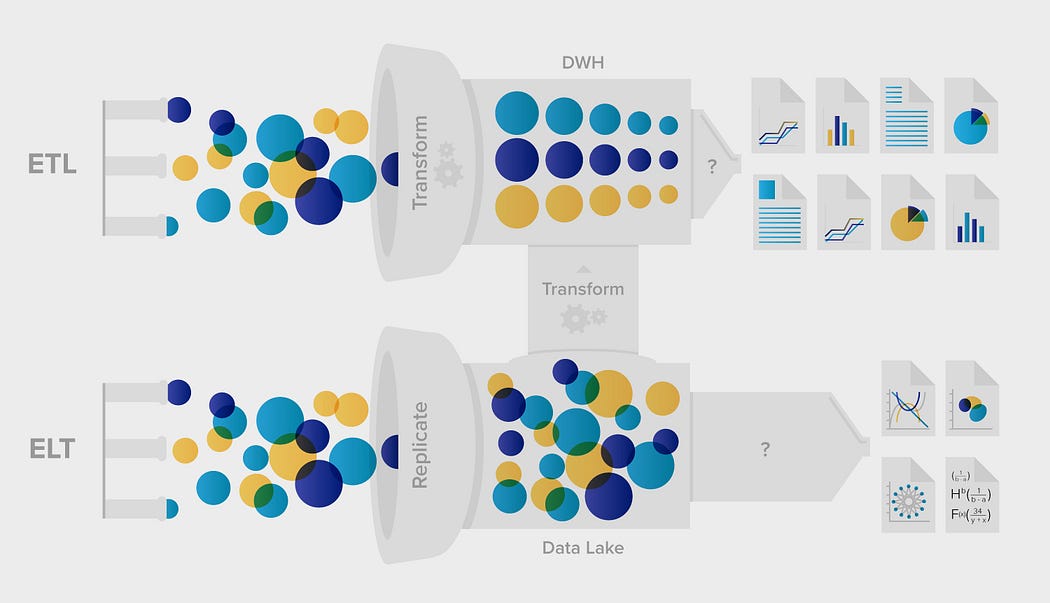
Comparison between the traditional ETL process for Data Warehouses to the ELT approach of Data Lakes. Notice that, in ETL, as opposed to ELT, the data needs to be arranged in a specific way (transformed) first before proceeding to get insights. This reflects the shift towards more agile and flexible data management practices in modern analytics.
Apache Hadoop: A foundational framework for storing and processing big data in a distributed environment. Hadoop’s HDFS (Hadoop Distributed File System) is often used as a storage layer for data lakes, providing reliable data storage for large datasets.
Apache Spark: An engine for large-scale data processing. Spark is known for its speed and ease of use in analytics applications. It can perform data transformations and analyses directly on data stored in a data lake, making it a powerful tool for driving insights.
Apache Airflow: An open-source workflow management tool that allows data engineers to automate and schedule data pipelines. Airflow is essential for managing complex data flows into and out of a data lake, ensuring that data is fresh and analytics are up-to-date.

Evaluating the impact of data lake initiatives is critical for understanding their value and guiding future investments. Key Performance Indicators (KPIs), data quality metrics, and Return on Investment (ROI) analyses serve as essential tools for assessing the effectiveness of data lakes.
Data Lake Health: Measures such as data ingestion rates, data processing times, and system uptime offer insights into the operational health of a data lake.
Data Quality Metrics: KPIs related to data accuracy, completeness, consistency, and timeliness help ensure that the data lake maintains high-quality data standards.
User Engagement: Metrics on user access patterns, query loads, and analytics usage provide feedback on how well the data lake meets the needs of its users.
Regular Audits: Conducting regular audits of data quality and usage patterns helps identify areas for improvement and ensures that the data lake remains aligned with business objectives.
Accessibility Measures: Tracking how easily users can find and access the data they need is crucial for fostering a data-driven culture and maximizing the value of the data lake.
Cost Savings: Comparing the operational costs before and after implementing a data lake can highlight efficiency gains.
Revenue Impact: Assessing how data lake insights have driven new revenue opportunities or enhanced customer experiences offers a direct link to business value.
Innovation and Agility: Evaluating the speed at which new data-driven products or services are developed and brought to market can demonstrate the strategic value of the data lake.
The landscape of data lake technology is continuously evolving, driven by advancements in artificial intelligence (AI), the Internet of Things (IoT), blockchain, and other emerging technologies.
Evolution of Data Lake Platforms and Ecosystems
Integration with Cloud and Hybrid Environments: The future will likely see deeper integration of data lakes with cloud services and hybrid infrastructures, enabling more flexible and scalable data architectures.
AI and Machine Learning: Enhanced AI capabilities will automate more aspects of data management and analytics, making data lakes even more powerful tools for insight generation.
IoT: The proliferation of IoT devices will lead to more real-time data streams into data lakes, necessitating advancements in data ingestion and processing capabilities.
Blockchain: Blockchain technology could provide new ways to secure and verify the integrity of data within lakes, especially in industries where data provenance is critical.
Data Fabric and Mesh Architectures: The concept of data fabric and mesh architectures might redefine data lakes, focusing on interconnectedness and accessibility across distributed environments.
Federated Analytics: Advances in federated learning and analytics will enable insights to be generated across multiple data lakes without compromising data privacy or security.
Data lakes play a pivotal role in enabling big data analytics, serving as the backbone for storing, processing, and analyzing vast amounts of diverse data. Their strategic importance to businesses continues to grow as companies seek to become more data-driven and agile in an increasingly competitive and complex marketplace. The journey of data lake evolution is ongoing, with new technologies and methodologies continuously emerging to enhance their capabilities and value. As businesses navigate this landscape, the focus remains on leveraging data lakes to unlock insights, drive innovation, and achieve sustainable growth.
The next time you sit down with your Chief Innovation Officer, bring up quality maturity as an agenda item. Artificial intelligence (AI) exists with …
READ MORE
AI has been an anticipated technological breakthrough, taking over most manual white-collar jobs today. PwC’s Global AI Study reveals that AI will …
READ MORE